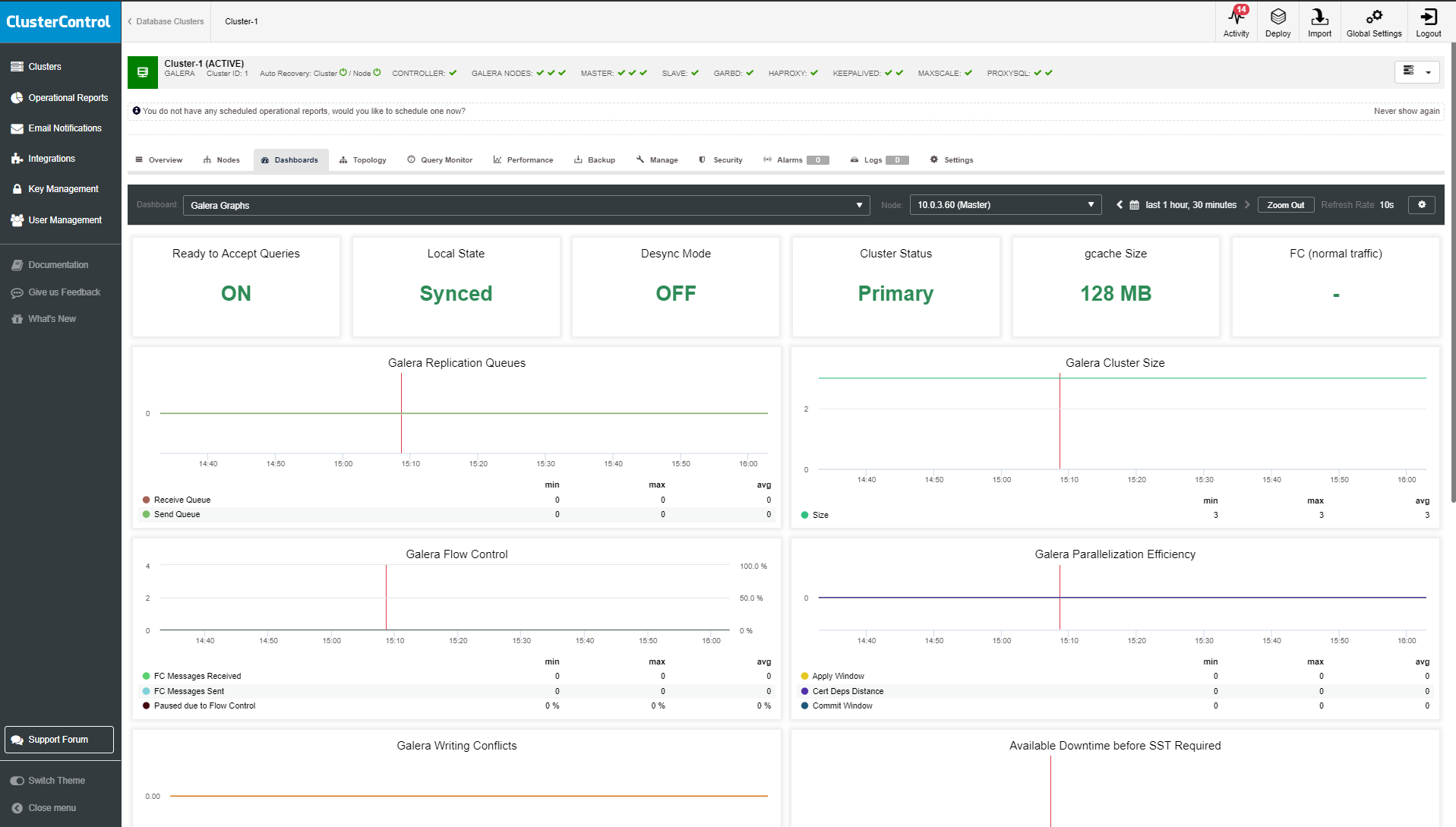
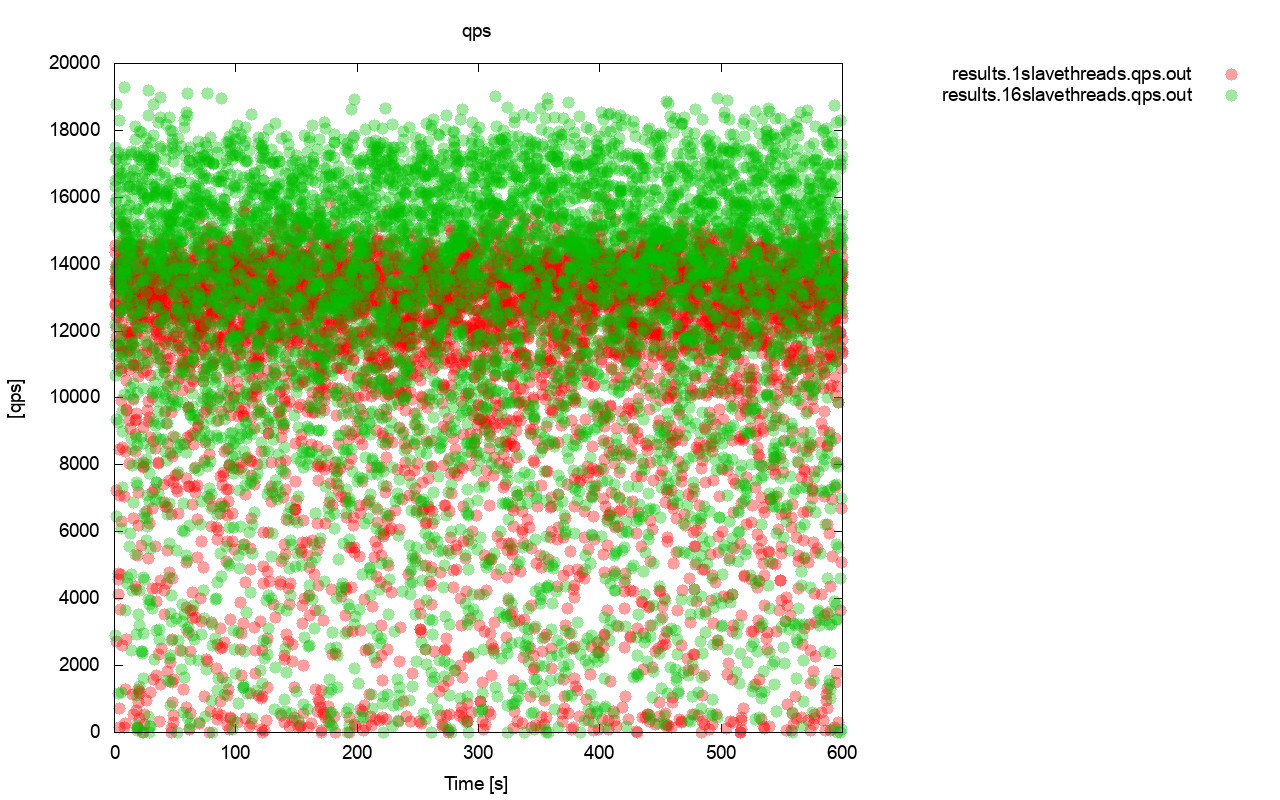
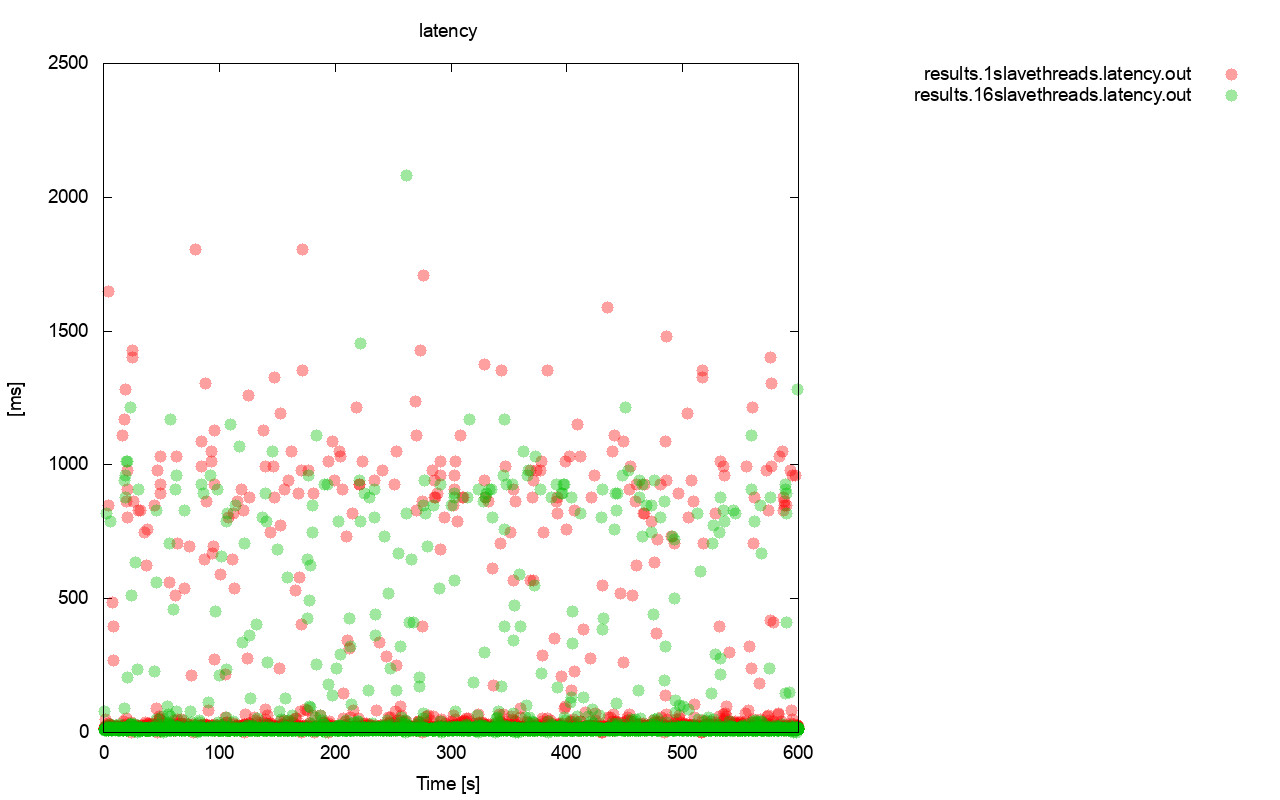
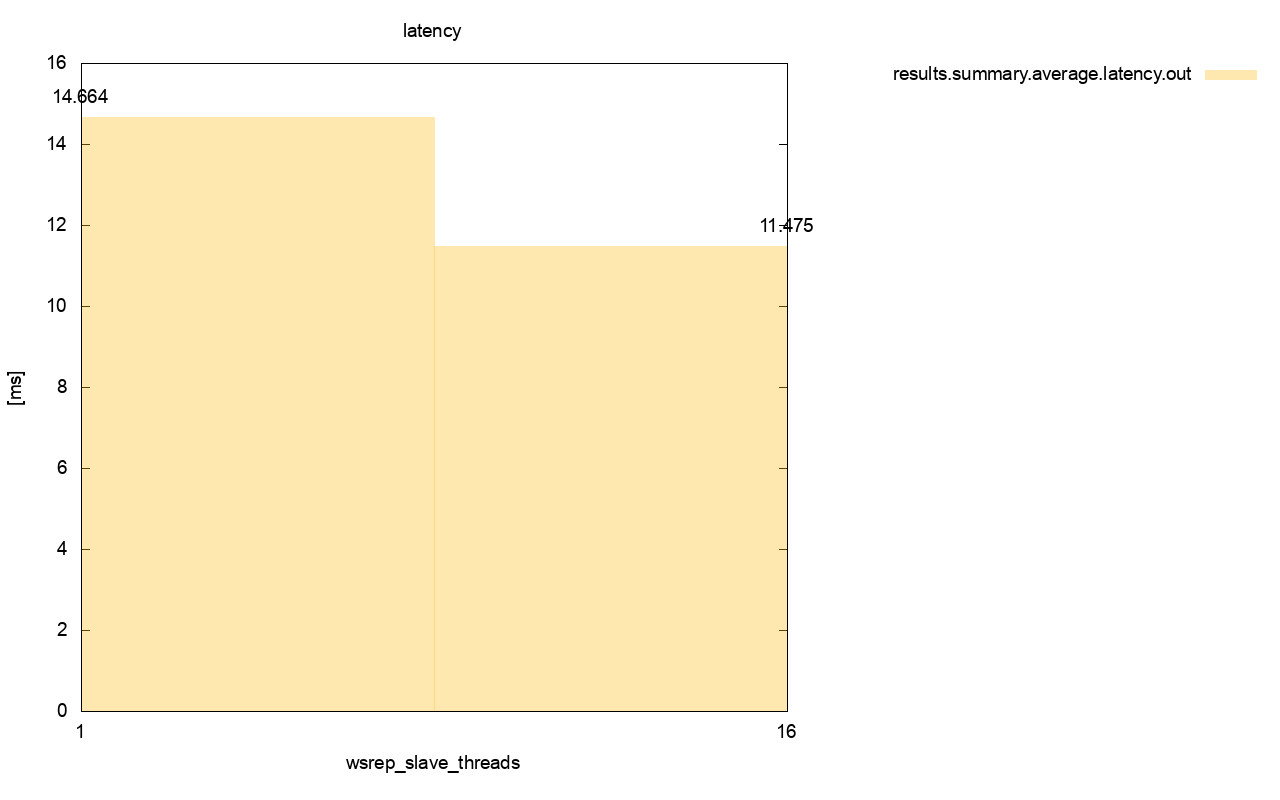
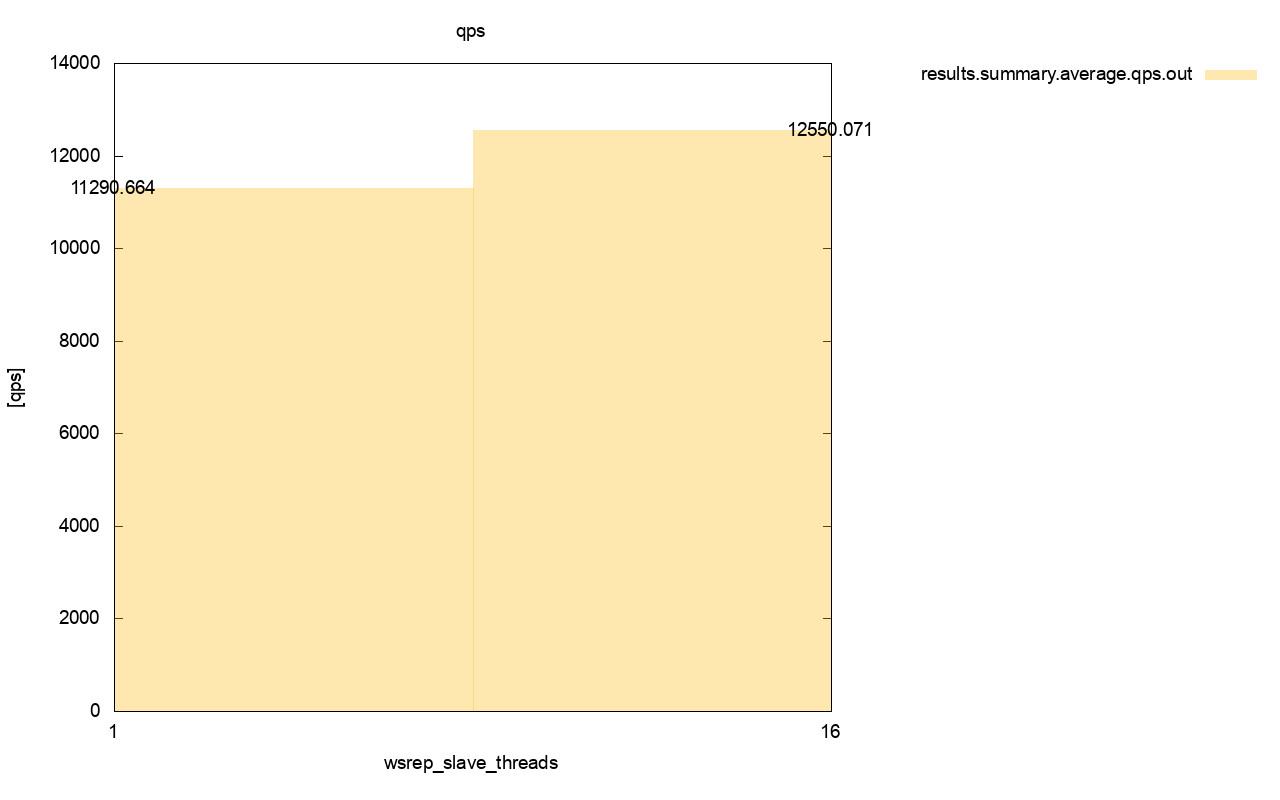
As we saw in the first part of this blog, a strongly consistent database cluster like Galera does not play well with container orchestration tools like Kubernetes or Swarm. We showed you how to deploy Galera and configure process management for Docker, so you retain full control of the behaviour. This blog post is the continuation of that, we are going to look into operation and maintenance of the cluster.
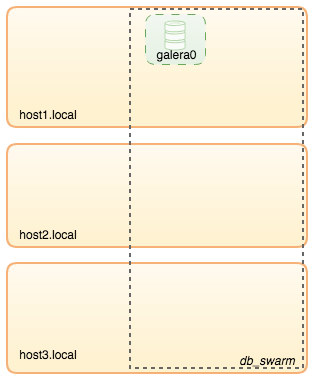
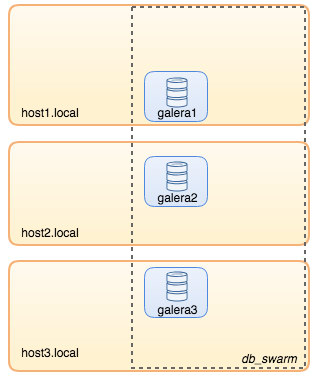
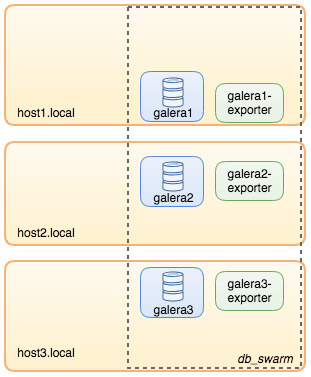
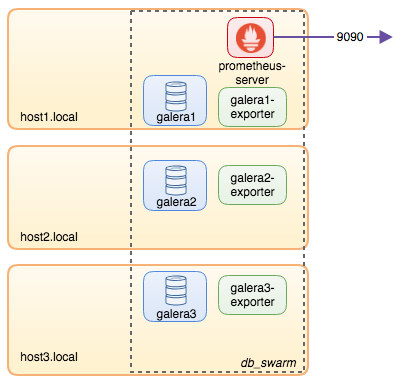
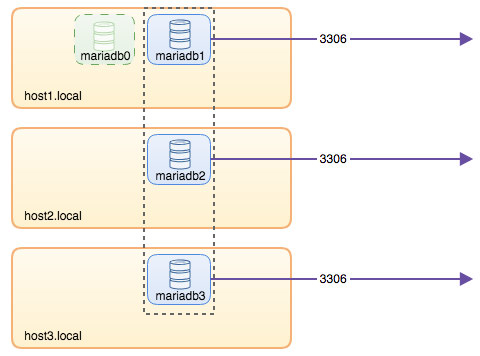
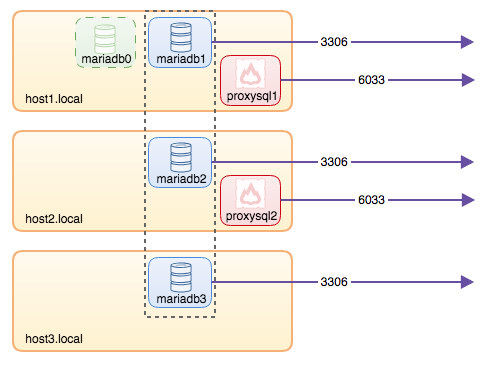
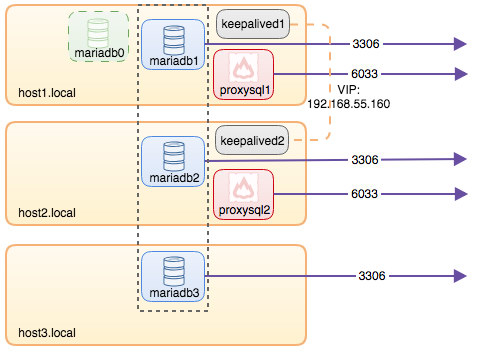
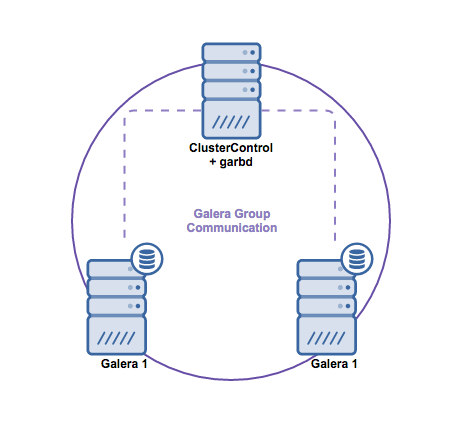
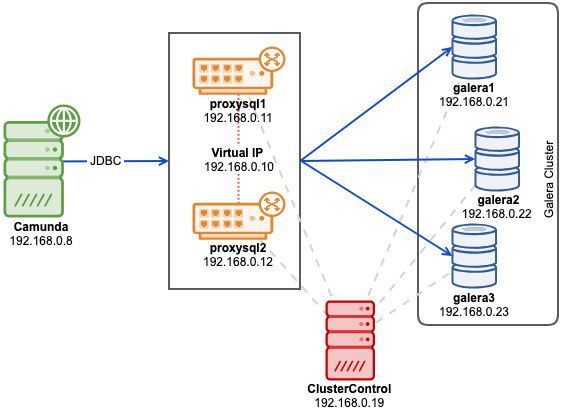
To recap some of the main points from the part 1 of this blog, we deployed a three-node Galera cluster, with ProxySQL and Keepalived on three different Docker hosts, where all MariaDB instances run as Docker containers. The following diagram illustrates the final deployment:

Graceful Shutdown
To perform a graceful MySQL shutdown, the best way is to send SIGTERM (signal 15) to the container:
$ docker kill -s 15 {db_container_name}If you would like to shutdown the cluster, repeat the above command on all database containers, one node at a time. The above is similar to performing "systemctl stop mysql" in systemd service for MariaDB. Using "docker stop" command is pretty risky for database service because it waits for 10 seconds timeout and Docker will force SIGKILL if this duration is exceeded (unless you use a proper --timeout value).
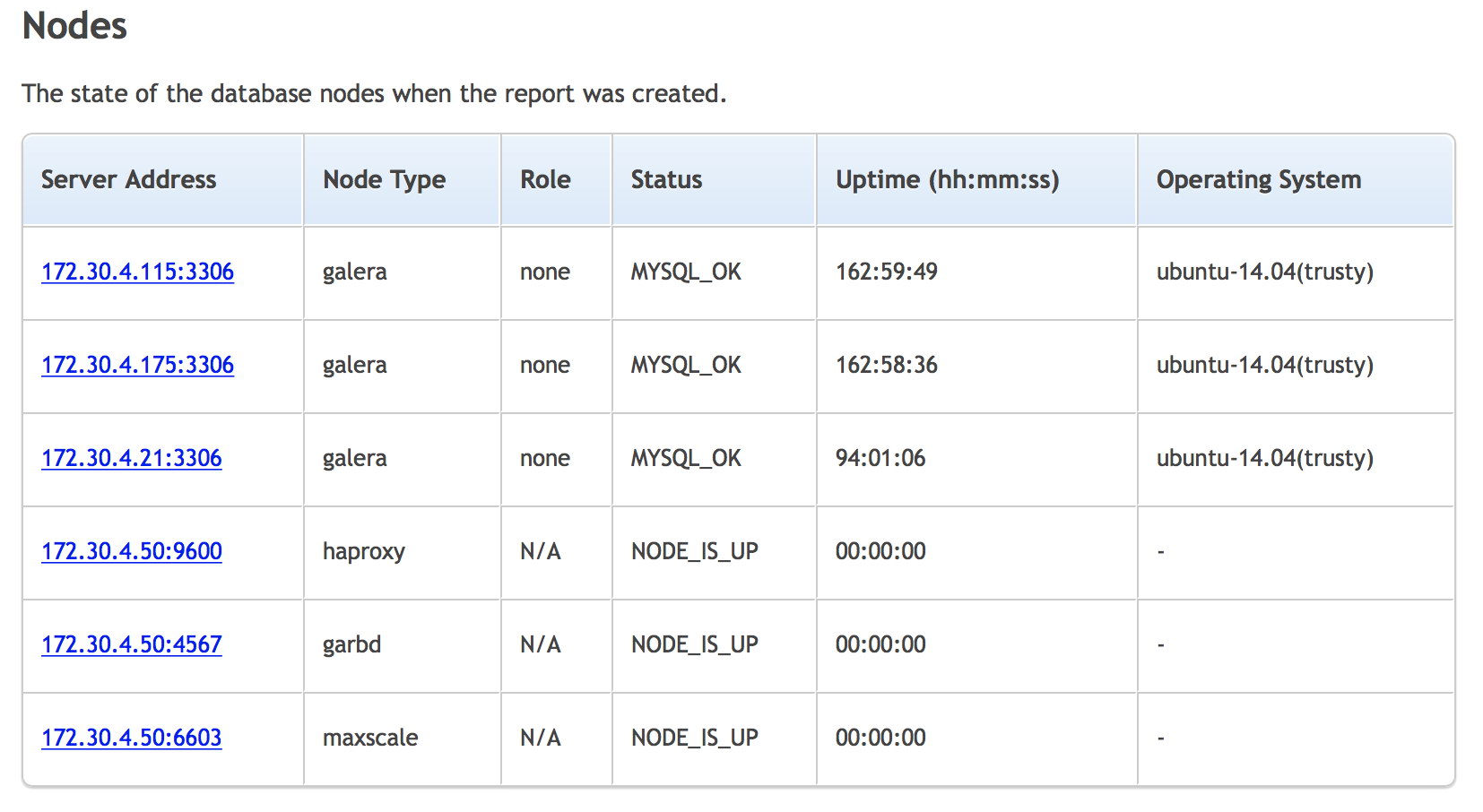
The last node that shuts down gracefully will have the seqno not equal to -1 and safe_to_bootstrap flag is set to 1 in the /{datadir volume}/grastate.dat of the Docker host, for example on host2:
$ cat /containers/mariadb2/datadir/grastate.dat
# GALERA saved state
version: 2.1
uuid: e70b7437-645f-11e8-9f44-5b204e58220b
seqno: 7099
safe_to_bootstrap: 1Detecting the Most Advanced Node
If the cluster didn't shut down gracefully, or the node that you were trying to bootstrap wasn't the last node to leave the cluster, you probably wouldn't be able to bootstrap one of the Galera node and might encounter the following error:
2016-11-07 01:49:19 5572 [ERROR] WSREP: It may not be safe to bootstrap the cluster from this node.
It was not the last one to leave the cluster and may not contain all the updates.
To force cluster bootstrap with this node, edit the grastate.dat file manually and set safe_to_bootstrap to 1 .Galera honours the node that has safe_to_bootstrap flag set to 1 as the first reference node. This is the safest way to avoid data loss and ensure the correct node always gets bootstrapped.
If you got the error, we have to find out the most advanced node first before picking up the node as the first to be bootstrapped. Create a transient container (with --rm flag), map it to the same datadir and configuration directory of the actual database container with two MySQL command flags, --wsrep_recover and --wsrep_cluster_address. For example, if we want to know mariadb1 last committed number, we need to run:
$ docker run --rm --name mariadb-recover \
--env MYSQL_ROOT_PASSWORD="PM7%cB43$sd@^1" \
--volume /containers/mariadb1/datadir:/var/lib/mysql \
--volume /containers/mariadb1/conf.d:/etc/mysql/conf.d \
mariadb:10.2.15 \
--wsrep_recover \
--wsrep_cluster_address=gcomm://
2018-06-12 4:46:35 139993094592384 [Note] mysqld (mysqld 10.2.15-MariaDB-10.2.15+maria~jessie) starting as process 1 ...
2018-06-12 4:46:35 139993094592384 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
...
2018-06-12 4:46:35 139993094592384 [Note] Plugin 'FEEDBACK' is disabled.
2018-06-12 4:46:35 139993094592384 [Note] Server socket created on IP: '::'.
2018-06-12 4:46:35 139993094592384 [Note] WSREP: Recovered position: e70b7437-645f-11e8-9f44-5b204e58220b:7099The last line is what we are looking for. MariaDB prints out the cluster UUID and the sequence number of the most recently committed transaction. The node which holds the highest number is deemed as the most advanced node. Since we specified --rm, the container will be removed automatically once it exits. Repeat the above step on every Docker host by replacing the --volume path to the respective database container volumes.
Once you have compared the value reported by all database containers and decided which container is the most up-to-date node, change the safe_to_bootstrap flag to 1 inside /{datadir volume}/grastate.dat manually. Let's say all nodes are reporting the same exact sequence number, we can just pick mariadb3 to be bootstrapped by changing the safe_to_bootstrap value to 1:
$ vim /containers/mariadb3/datadir/grasate.dat
...
safe_to_bootstrap: 1Save the file and start bootstrapping the cluster from that node, as described in the next chapter.
Bootstrapping the Cluster
Bootstrapping the cluster is similar to the first docker run command we used when starting up the cluster for the first time. If mariadb1 is the chosen bootstrap node, we can simply re-run the created bootstrap container:
$ docker start mariadb0 # on host1Otherwise, if the bootstrap container does not exist on the chosen node, let's say on host2, run the bootstrap container command and map the existing mariadb2's volumes. We are using mariadb0 as the container name on host2 to indicate it is a bootstrap container:
$ docker run -d \
--name mariadb0 \
--hostname mariadb0.weave.local \
--net weave \
--publish "3306" \
--publish "4444" \
--publish "4567" \
--publish "4568" \
$(weave dns-args) \
--env MYSQL_ROOT_PASSWORD="PM7%cB43$sd@^1" \
--volume /containers/mariadb2/datadir:/var/lib/mysql \
--volume /containers/mariadb2/conf.d:/etc/mysql/mariadb.conf.d \
mariadb:10.2.15 \
--wsrep_cluster_address=gcomm:// \
--wsrep_sst_auth="root:PM7%cB43$sd@^1" \
--wsrep_node_address=mariadb0.weave.localYou may notice that this command is slightly shorter as compared to the previous bootstrap command described in this guide. Since we already have the proxysql user created in our first bootstrap command, we may skip these two environment variables:
- --env MYSQL_USER=proxysql
- --env MYSQL_PASSWORD=proxysqlpassword
Then, start the remaining MariaDB containers, remove the bootstrap container and start the existing MariaDB container on the bootstrapped host. Basically the order of commands would be:
$ docker start mariadb1 # on host1
$ docker start mariadb3 # on host3
$ docker stop mariadb0 # on host2
$ docker start mariadb2 # on host2At this point, the cluster is started and is running at full capacity.
Resource Control
Memory is a very important resource in MySQL. This is where the buffers and caches are stored, and it's critical for MySQL to reduce the impact of hitting the disk too often. On the other hand, swapping is bad for MySQL performance. By default, there will be no resource constraints on the running containers. Containers use as much of a given resource as the host’s kernel will allow. Another important thing is file descriptor limit. You can increase the limit of open file descriptor, or "nofile" to something higher to cater for the number of files MySQL server can open simultaneously. Setting this to a high value won't hurt.
To cap memory allocation and increase the file descriptor limit to our database container, one would append --memory, --memory-swap and --ulimit parameters into the "docker run" command:
$ docker kill -s 15 mariadb1
$ docker rm -f mariadb1
$ docker run -d \
--name mariadb1 \
--hostname mariadb1.weave.local \
--net weave \
--publish "3306:3306" \
--publish "4444" \
--publish "4567" \
--publish "4568" \
$(weave dns-args) \
--memory 16g \
--memory-swap 16g \
--ulimit nofile:16000:16000 \
--env MYSQL_ROOT_PASSWORD="PM7%cB43$sd@^1" \
--volume /containers/mariadb1/datadir:/var/lib/mysql \
--volume /containers/mariadb1/conf.d:/etc/mysql/mariadb.conf.d \
mariadb:10.2.15 \
--wsrep_cluster_address=gcomm://mariadb0.weave.local,mariadb1.weave.local,mariadb2.weave.local,mariadb3.weave.local \
--wsrep_sst_auth="root:PM7%cB43$sd@^1" \
--wsrep_node_address=mariadb1.weave.localTake note that if --memory-swap is set to the same value as --memory, and --memory is set to a positive integer, the container will not have access to swap. If --memory-swap is not set, container swap will default to --memory multiply by 2. If --memory and --memory-swap are set to the same value, this will prevent containers from using any swap. This is because --memory-swap is the amount of combined memory and swap that can be used, while --memory is only the amount of physical memory that can be used.
Some of the container resources like memory and CPU can be controlled dynamically through "docker update" command, as shown in the following example to upgrade the memory of container mariadb1 to 32G on-the-fly:
$ docker update \
--memory 32g \
--memory-swap 32g \
mariadb1Do not forget to tune the my.cnf accordingly to suit the new specs. Configuration management is explained in the next section.
Configuration Management
Most of the MySQL/MariaDB configuration parameters can be changed during runtime, which means you don't need to restart to apply the changes. Check out the MariaDB documentation page for details. The parameter listed with "Dynamic: Yes" means the variable is loaded immediately upon changing without the necessity to restart MariaDB server. Otherwise, set the parameters inside the custom configuration file in the Docker host. For example, on mariadb3, make the changes to the following file:
$ vim /containers/mariadb3/conf.d/my.cnfAnd then restart the database container to apply the change:
$ docker restart mariadb3Verify the container starts up the process by looking at the docker logs. Perform this operation on one node at a time if you would like to make cluster-wide changes.
Backup
Taking a logical backup is pretty straightforward because the MariaDB image also comes with mysqldump binary. You simply use the "docker exec" command to run the mysqldump and send the output to a file relative to the host path. The following command performs mysqldump backup on mariadb2 and saves it to /backups/mariadb2 inside host2:
$ docker exec -it mariadb2 mysqldump -uroot -p --single-transaction > /backups/mariadb2/dump.sqlBinary backup like Percona Xtrabackup or MariaDB Backup requires the process to access the MariaDB data directory directly. You have to either install this tool inside the container, or through the machine host or use a dedicated image for this purpose like "perconalab/percona-xtrabackup" image to create the backup and stored it inside /tmp/backup on the Docker host:
$ docker run --rm -it \
-v /containers/mariadb2/datadir:/var/lib/mysql \
-v /tmp/backup:/xtrabackup_backupfiles \
perconalab/percona-xtrabackup \
--backup --host=mariadb2 --user=root --password=mypasswordYou can also stop the container with innodb_fast_shutdown set to 0 and copy over the datadir volume to another location in the physical host:
$ docker exec -it mariadb2 mysql -uroot -p -e 'SET GLOBAL innodb_fast_shutdown = 0'
$ docker kill -s 15 mariadb2
$ cp -Rf /containers/mariadb2/datadir /backups/mariadb2/datadir_copied
$ docker start mariadb2Restore
Restoring is pretty straightforward for mysqldump. You can simply redirect the stdin into the container from the physical host:
$ docker exec -it mariadb2 mysql -uroot -p < /backups/mariadb2/dump.sqlYou can also use the standard mysql client command line remotely with proper hostname and port value instead of using this "docker exec" command:
$ mysql -uroot -p -h127.0.0.1 -P3306 < /backups/mariadb2/dump.sqlFor Percona Xtrabackup and MariaDB Backup, we have to prepare the backup beforehand. This will roll forward the backup to the time when the backup was finished. Let's say our Xtrabackup files are located under /tmp/backup of the Docker host, to prepare it, simply:
$ docker run --rm -it \
-v mysql-datadir:/var/lib/mysql \
-v /tmp/backup:/xtrabackup_backupfiles \
perconalab/percona-xtrabackup \
--prepare --target-dir /xtrabackup_backupfilesThe prepared backup under /tmp/backup of the Docker host then can be used as the MariaDB datadir for a new container or cluster. Let's say we just want to verify restoration on a standalone MariaDB container, we would run:
$ docker run -d \
--name mariadb-restored \
--env MYSQL_ROOT_PASSWORD="PM7%cB43$sd@^1" \
-v /tmp/backup:/var/lib/mysql \
mariadb:10.2.15If you performed a backup using stop and copy approach, you can simply duplicate the datadir and use the duplicated directory as a volume maps to MariaDB datadir to run on another container. Let's say the backup was copied over under /backups/mariadb2/datadir_copied, we can run a new container by running:
$ mkdir -p /containers/mariadb-restored/datadir
$ cp -Rf /backups/mariadb2/datadir_copied /containers/mariadb-restored/datadir
$ docker run -d \
--name mariadb-restored \
--env MYSQL_ROOT_PASSWORD="PM7%cB43$sd@^1" \
-v /containers/mariadb-restored/datadir:/var/lib/mysql \
mariadb:10.2.15The MYSQL_ROOT_PASSWORD must match the actual root password for that particular backup.
Database Version Upgrade
There are two types of upgrade - in-place upgrade or logical upgrade.
In-place upgrade involves shutting down the MariaDB server, replacing the old binaries with the new binaries and then starting the server on the old data directory. Once started, you have to run mysql_upgrade script to check and upgrade all system tables and also to check the user tables.
The logical upgrade involves exporting SQL from the current version using a logical backup utility such as mysqldump, running the new container with the upgraded version binaries, and then applying the SQL to the new MySQL/MariaDB version. It is similar to backup and restore approach described in the previous section.
Nevertheless, it's a good approach to always backup your database before performing any destructive operations. The following steps are required when upgrading from the current image, MariaDB 10.1.33 to another major version, MariaDB 10.2.15 on mariadb3 resides on host3:
Backup the database. It doesn't matter physical or logical backup but the latter using mysqldump is recommended.
Download the latest image that we would like to upgrade to:
$ docker pull mariadb:10.2.15Set innodb_fast_shutdown to 0 for our database container:
$ docker exec -it mariadb3 mysql -uroot -p -e 'SET GLOBAL innodb_fast_shutdown = 0'Graceful shut down the database container:
$ docker kill --signal=TERM mariadb3Create a new container with the new image for our database container. Keep the rest of the parameters intact except using the new container name (otherwise it would conflict):
$ docker run -d \ --name mariadb3-new \ --hostname mariadb3.weave.local \ --net weave \ --publish "3306:3306" \ --publish "4444" \ --publish "4567" \ --publish "4568" \ $(weave dns-args) \ --env MYSQL_ROOT_PASSWORD="PM7%cB43$sd@^1" \ --volume /containers/mariadb3/datadir:/var/lib/mysql \ --volume /containers/mariadb3/conf.d:/etc/mysql/mariadb.conf.d \ mariadb:10.2.15 \ --wsrep_cluster_address=gcomm://mariadb0.weave.local,mariadb1.weave.local,mariadb2.weave.local,mariadb3.weave.local \ --wsrep_sst_auth="root:PM7%cB43$sd@^1" \ --wsrep_node_address=mariadb3.weave.localRun mysql_upgrade script:
$ docker exec -it mariadb3-new mysql_upgrade -uroot -pIf no errors occurred, remove the old container, mariadb3 (the new one is mariadb3-new):
$ docker rm -f mariadb3Otherwise, if the upgrade process fails in between, we can fall back to the previous container:
$ docker stop mariadb3-new $ docker start mariadb3
Major version upgrade can be performed similarly to the minor version upgrade, except you have to keep in mind that MySQL/MariaDB only supports major upgrade from the previous version. If you are on MariaDB 10.0 and would like to upgrade to 10.2, you have to upgrade to MariaDB 10.1 first, followed by another upgrade step to MariaDB 10.2.
Take note on the configuration changes being introduced and deprecated between major versions.
Failover
In Galera, all nodes are masters and hold the same role. With ProxySQL in the picture, connections that pass through this gateway will be failed over automatically as long as there is a primary component running for Galera Cluster (that is, a majority of nodes are up). The application won't notice any difference if one database node goes down because ProxySQL will simply redirect the connections to the other available nodes.
If the application connects directly to the MariaDB bypassing ProxySQL, failover has to be performed on the application-side by pointing to the next available node, provided the database node meets the following conditions:
- Status wsrep_local_state_comment is Synced (The state "Desynced/Donor" is also possible, only if wsrep_sst_method is xtrabackup, xtrabackup-v2 or mariabackup).
- Status wsrep_cluster_status is Primary.
In Galera, an available node doesn't mean it's healthy until the above status are verified.
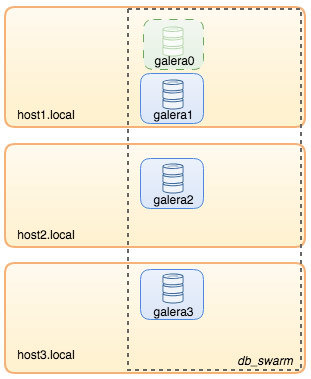
Scaling Out
To scale out, we can create a new container in the same network and use the same custom configuration file for the existing container on that particular host. For example, let's say we want to add the fourth MariaDB container on host3, we can use the same configuration file mounted for mariadb3, as illustrated in the following diagram:

Run the following command on host3 to scale out:
$ docker run -d \
--name mariadb4 \
--hostname mariadb4.weave.local \
--net weave \
--publish "3306:3307" \
--publish "4444" \
--publish "4567" \
--publish "4568" \
$(weave dns-args) \
--env MYSQL_ROOT_PASSWORD="PM7%cB43$sd@^1" \
--volume /containers/mariadb4/datadir:/var/lib/mysql \
--volume /containers/mariadb3/conf.d:/etc/mysql/mariadb.conf.d \
mariadb:10.2.15 \
--wsrep_cluster_address=gcomm://mariadb1.weave.local,mariadb2.weave.local,mariadb3.weave.local,mariadb4.weave.local \
--wsrep_sst_auth="root:PM7%cB43$sd@^1" \
--wsrep_node_address=mariadb4.weave.localOnce the container is created, it will join the cluster and perform SST. It can be accessed on port 3307 externally or outside of the Weave network, or port 3306 within the host or within the Weave network. It's not necessary to include mariadb0.weave.local into the cluster address anymore. Once the cluster is scaled out, we need to add the new MariaDB container into the ProxySQL load balancing set via admin console:
$ docker exec -it proxysql1 mysql -uadmin -padmin -P6032
mysql> INSERT INTO mysql_servers(hostgroup_id,hostname,port) VALUES (10,'mariadb4.weave.local',3306);
mysql> INSERT INTO mysql_servers(hostgroup_id,hostname,port) VALUES (20,'mariadb4.weave.local',3306);
mysql> LOAD MYSQL SERVERS TO RUNTIME;
mysql> SAVE MYSQL SERVERS TO DISK;Repeat the above commands on the second ProxySQL instance.
Finally for the the last step, (you may skip this part if you already ran "SAVE .. TO DISK" statement in ProxySQL), add the following line into proxysql.cnf to make it persistent across container restart on host1 and host2:
$ vim /containers/proxysql1/proxysql.cnf # host1
$ vim /containers/proxysql2/proxysql.cnf # host2And append mariadb4 related lines under mysql_server directive:
mysql_servers =
(
{ address="mariadb1.weave.local" , port=3306 , hostgroup=10, max_connections=100 },
{ address="mariadb2.weave.local" , port=3306 , hostgroup=10, max_connections=100 },
{ address="mariadb3.weave.local" , port=3306 , hostgroup=10, max_connections=100 },
{ address="mariadb4.weave.local" , port=3306 , hostgroup=10, max_connections=100 },
{ address="mariadb1.weave.local" , port=3306 , hostgroup=20, max_connections=100 },
{ address="mariadb2.weave.local" , port=3306 , hostgroup=20, max_connections=100 },
{ address="mariadb3.weave.local" , port=3306 , hostgroup=20, max_connections=100 },
{ address="mariadb4.weave.local" , port=3306 , hostgroup=20, max_connections=100 }
)Save the file and we should be good on the next container restart.
Scaling Down
To scale down, simply shuts down the container gracefully. The best command would be:
$ docker kill -s 15 mariadb4
$ docker rm -f mariadb4Remember, if the database node left the cluster ungracefully, it was not part of scaling down and would affect the quorum calculation.
To remove the container from ProxySQL, run the following commands on both ProxySQL containers. For example, on proxysql1:
$ docker exec -it proxysql1 mysql -uadmin -padmin -P6032
mysql> DELETE FROM mysql_servers WHERE hostname="mariadb4.weave.local";
mysql> LOAD MYSQL SERVERS TO RUNTIME;
mysql> SAVE MYSQL SERVERS TO DISK;You can then either remove the corresponding entry inside proxysql.cnf or just leave it like that. It will be detected as OFFLINE from ProxySQL point-of-view anyway.
Summary
With Docker, things get a bit different from the conventional way on handling MySQL or MariaDB servers. Handling stateful services like Galera Cluster is not as easy as stateless applications, and requires proper testing and planning.
In our next blog on this topic, we will evaluate the pros and cons of running Galera Cluster on Docker without any orchestration tools.